Seven roads to data-driven value creation
2017-09-10
last modified: 2023-05-15
1. Predict

Predicting crime

Predicting deals

Predictive maintenance

2. Suggest

Amazon’s product recommendation system

Google’s “Related searches…”

Retailer’s personalized recommendations

3. Curate

Clarivate Analytics curating metadata(data, data curation) from scientific publishing

Nielsen and IRI curating and selling retail data


ImDB curating and selling movie data

NomadList providing practical info on global cities for nomad workers

4. Enrich

Selling methods and tools to enrich datasets

Selling aggregated indicators

Selling credit scores
5. Rank / match / compare
Search engines ranking results
Yelp, Tripadvisor, etc… which rank places

Any system that needs to filter out best quality entities among a crowd of candidates
6. Segment / classify

Tools for discovery / exploratory analysis by segmentation
Diagnostic tools (spam or not? buy, hold or sell? healthy or not?)

7. Generate / synthesize

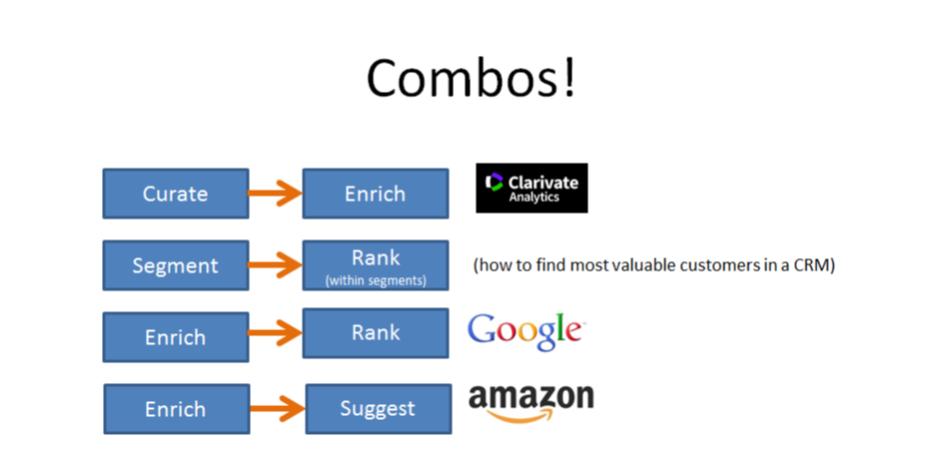
Combos
The end
Find references for this lesson, and other lessons, here.

This course is made by Clement Levallois.
Discover my other courses in data / tech for business: https://www.clementlevallois.net
Or get in touch via Twitter: @seinecle